Адрес для входа в РФ: toffler.online
Ошибки искусственного интеллекта
 Так ChatGPT представляет себе искусственный интеллект в графическом изображении
Так ChatGPT представляет себе искусственный интеллект в графическом изображении
Те, кто пользуются различными моделями искусственного интеллекта, знают, что ИИ часто лажают. При этом интересно было бы узнать, какой процент ошибок допускают различные ИИ. Исследовательская группа Tow Center провела такое исследование: они изучили восемь поисковых систем с искусственным интеллектом, включая ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search и Copilot, проверили каждую из них на точность и записали, как часто эти модели отказывались отвечать.
Исследователи случайным образом выбрали 200 новостных статей от 20 новостных издательств (по 10 от каждого). Они убедились, что каждая статья попадает в первые три результата поиска Google при использовании цитируемого отрывка из статьи. Затем они выполнили тот же запрос в каждом из инструментов поиска ИИ и оценили точность поиска по тому, правильно ли были указаны А) статья, Б) новостная организация и В) URL.
Затем исследователи промаркировали каждый поиск по степени точности от «полностью верного» до «полностью неверного». Как видно из приведенной ниже диаграммы, кроме обеих версий Perplexity, ИИ не показали высоких результатов. В совокупности поисковые системы ИИ ошибаются в 60% случаев. Более того, эти неверные результаты подкреплялись "уверенностью" ИИ в них.
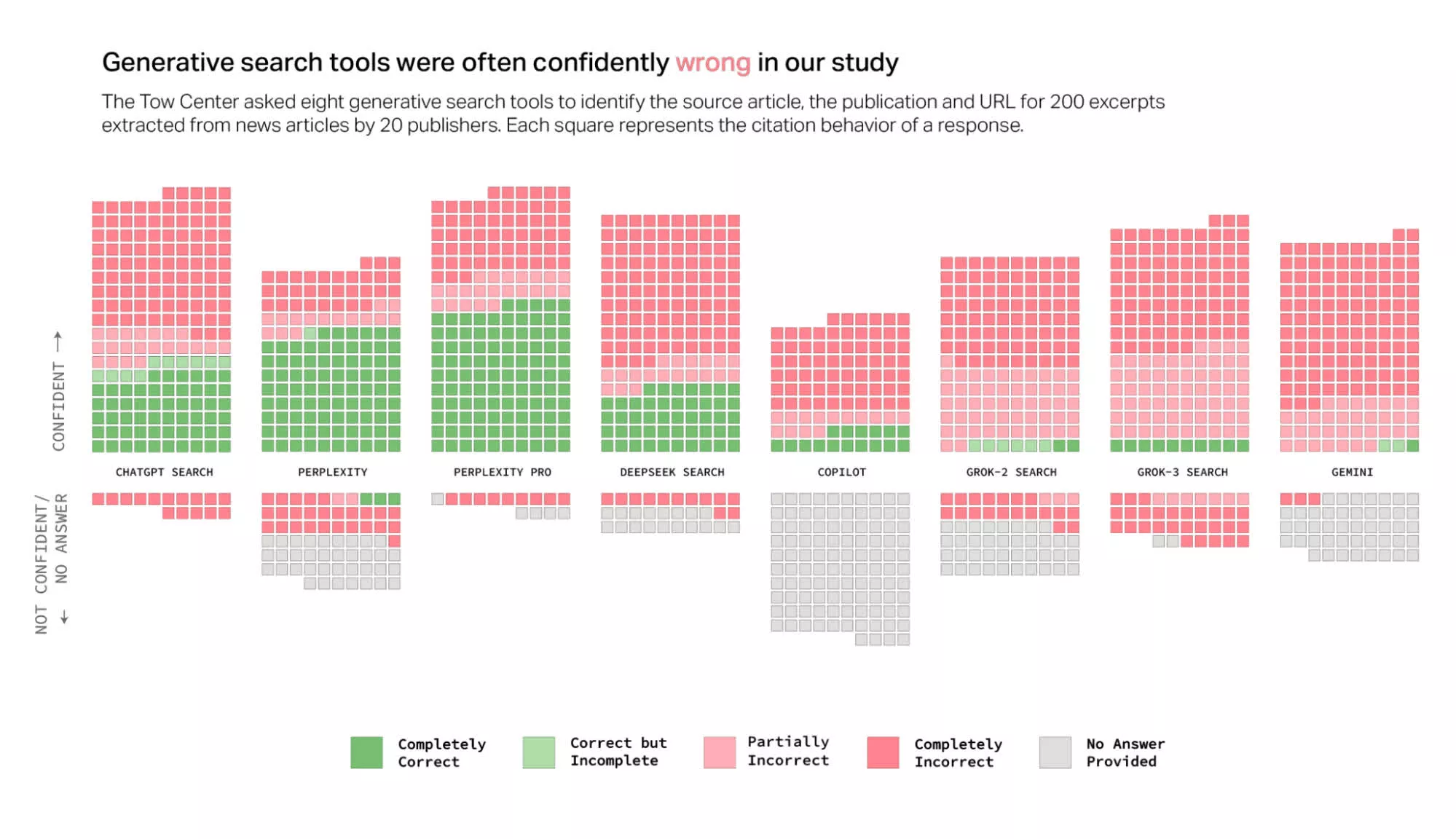
Что интересно, даже признав свою неправоту, ChatGPT дополняет это признание еще более сфабрикованной информацией. Похоже, что ИИ запрограммирован на то, чтобы любой ценой отвечать на каждый запрос пользователя. Данные исследователя подтверждают эту гипотезу: ChatGPT Search был единственным инструментом ИИ, который ответил на все 200 запросов по статьям. Однако его точность составила всего 28%, а полная неточность - 57% случаев.
Причем ChatGPT даже не самый плохой из всех. Обе версии ИИ Grok от X показали низкие результаты, а Grok-3 Search оказался неточным на 94%. Copilot от Microsoft оказался не намного лучше, если учесть, что он отказался отвечать на 104 запроса из 200. Из оставшихся 96 только 16 были «полностью правильными», 14 - «частично правильными» и 66 - «полностью неправильными», что составляет примерно 70% неточностей.
Компании, создающие эти модели, берут с публики от 20 до 200 долларов в месяц за доступ. При этом Perplexity Pro (20 долларов в месяц) и Grok-3 Search (40 долларов в месяц) ответили на большее количество запросов правильно, чем их бесплатные версии (Perplexity и Grok-2 Search), но при этом имели значительно более высокий уровень ошибок.
Ну и сами исследователи, сравнивающее выдачу ИИ с выдачей гугла - похоже, не семи пядей во лбу, если только не выполняют чей-то заказ.
Суть в том, что ИИ вообще не предназначен для того, чтобы выдвать вам правильные ответы, совпадающие в выборкой гугла - для этого уже гугл есть.
"ИИ", который в данном случае представлен различными версиями LLM - это всего лишь ГЕНЕРАТОР ТЕКСТА, использующий статистические зависимости между словами в обучающей выборке и промпте и для построения последовательности, которая выглядит как осмысленный текст. Не больше, и не меньше. Это не гугл. Он ничего не ищет. Он просто генерит статически наиболее релевантный текст. Если в его выборке нет высокорелевантной (то есть, вероятно, правильной, но, на самом деле, часто встречающейся) последовательности, он сгенерит менее релевантную - просто ту, которая статистически более вероятна. У него нет мозгов, он не может верифицировать ответ, и не умеет сказать: "Не знаю".
Вовсе нет. Такую стадию ии-модели проходят только на этапе обучения языку. Дальше их учат отвечать так, как от них ожидается, вот там уже появляется «разум».

– Чего тебе?
– Босс хочет вас видеть. Немедленно. Как только появитесь.
– Хорошо,
– Р. Сэмми не двинулся с места.
– Я сказал, хорошо. Можешь уходить!
Р. Сэмми круто развернулся и отправился выполнять другие поручения.
«И почему им заменили человека?» – раздраженно подумал Бейли.
– Я бы дал пинка под зад этому Р. Сэмми, если б не боялся сломать себе ногу, – сказал Симпсон. – На днях видел Винса Барретта.
– Да?
– Он хотел бы снова работать на прежнем месте. Или на любом другом, лишь бы у нас в департаменте. Бедняга в отчаянии, но что я мог ему посоветовать? Его обязанности уже выполняет Р. Сэмми, и ничего тут не поделать. Малышу сейчас приходится работать на конвейере на дрожжевой фабрике. Смышленый был малый. Всем нравился.
Бейли пожал плечами и сказал несколько строже, чем хотел:
– Сейчас такое время, что подобное с каждым может случиться.
Представил, будто мне нужно сделать простенький инженерный расчет, я не хочу напрягаться и читать учебников, а тупо забиваю исходные в окошко и жду результата.
Использовал: ChatGPT, Perplexity, Gemini, Grok и Copilot.
Итог: у всех ИИ результаты расчета ошибочны (кроме Gemini), и у всех разные.
Gemini - в ответе много общих слов и ни одной конкретной цифры. Но зато и не соврал, просто процитировал какой-то учебник по теме.
ChatGPT - пытался в формулы, ошибся сильнее всех, результаты отличаются от реальных на два порядка вверх.
Perplexity - оформление с претензией на что-то умное, считал долго, формулы странные неизвестно откуда откопал, в результате один параметр посчитал близко к реальному , во втором ошибся на порядок вниз.
Copilot - формулы плюс-минус нормальные, справочные данные накопал ошибочные, в итоге один параметр - близко, второй - совсем не то, на два порядка вниз.
Grok - формулы плюс-минус нормальные (но записаны по идиотски), справочные данные накопал частично правильные, частично враньё, в итоге - оба параметра посчитаны, скажем так, близко к реальности, но опытный инженер их не примет.
В целом впечатление, что математику они знают, физику - хуже, справочные данные откапывают неизвестно где. Верить нельзя никому.
Студент технического вуза со справочниками 50-летней давности справился бы лучше.
Claude-ом что, религия пользоваться не позволяет? Можно же e-sim завести для номера.
А для того чтобы решить вашу задачу - вам понадобиться отдельная нейросетка - тренированная именно на тех же учебниках и потом еще возможно с кучей условий откорректированных тем же студентом )
Вот и вся петрушка , и весь "ИИ" ) ....

Если вдуматься, а как в принципе можно создать такой интеллект, который не будет косячить? У него там в середине будет встроен философский камень? 😉 Я хочу сказать - не будет ли при любой степени развития ИИ способен ошибаться? Сейчас он ошибается много, да. Потом он станет ошибаться меньше чем человек. Но все равно, видимо, будет. А если не нравится - ну что ж, вычисляй тогда ответ сам, на безошибочном калькуляторе.
Можно еще передать задание человеческим помошникам. Ну там, секретарше, например. Или джуну, если ты синьор. Которые, правда, тоже могут накосячить. И вопрос о доверии к результатам их "дип ресерча" все равно присутствует.
Передавая друг-другу тонны чуши.
И что? Блин, да 10 лет на человека, который бы рассказывал про чятжпт или стейблдифужн смотрели бы, как на идиота, обчитавшегося фантастики и впавшего в маразм.
Даже с поиском, который у ии не самая сильная сторона, чаще помогает, чем нет. И, в отличие от поисковиков, помогает искать по неточным запросам. Даже когда находит не то, чаще всего даёт достаточно отправных точек, чтобы искать дальше.
А народ жалуется, что ему приготовили, но в рот не положили и не прожевали.
Какие-то просьбы рассчитать маршрут, найти компании перевозок, которые занимаются чем-то определенным и так далее - лажал по страшному. Причем брал данные с таких сайтов, как реддит, всякие форумы, отзывы - где люди могут писать что угодно. Грок, также напирал на твиттеровские посты. В общем, хрень полная, инфа от балды совершенно.


И чего тогда ждать от ИИ?!
И, кстати - сидя в "чистой комнате" мир не познаешь))
Или нанимают профессионалов писать тексты чисто для обучения
Позавчера детеньіш в школе делала доклад по истории. После доклада, по традиции - докладчик задает вопросьі классу. Учитель: "судя по всему (по их самостоятельньім работам) - вьі любите Чат ГПТ и прочие системьі. Поєтому, кто невнимательно слушал доклад - могут пользоваться ими".
По словам детеньіша - ей в єтот раз удалось сильно сєкономить на конфетках (у них правило: за верньій ответ - конфетка) за счет того, что народ ломанулся спрашивать у електрической чудищи и чудища нагородила херни.
Хотя вроде в самом нике две буквы ы нормальные написаны.
никакого ИИ нет , - все гроки и чатгпт и иже с ними , это не более чем продвинутая и дружелюбная к пользователю СУБД ...
с точки зрения принципов работы всего этого и маркетинга - EXCEL тоже ИИ ))
Перцептрон Розенблатта передает всем привет из 1957 года ...
Кончится это все тоже предсказуемо , как кончился кризис Доткомов ...,Железнодорожный кризис в Британии , Телеграфный кризис , - биржевыми крахами ) ......
а технологии останутся, без хайпа конечно )
с точки зрения принципов работы всего этого и маркетинга - EXCEL тоже ИИ ))
никакого ИИ нет , - все гроки и чатгпт и иже с ними , это не более чем продвинутая и дружелюбная к пользователю СУБД ...
"Как построить свою экспертную систему"
Автор: Нейлор Крис
Издание 1991
lib.ysu.am
Я же говорю про обычного человека, а не про того, который изучает эти нейросети, следит за ними и специфически их использует. Обычный человек не ищет какие-то специальные интервью, он живет в общественном информационном поле. А там именно тот хайп вокруг ИИ про который я говорю.
Для начала напомним, что Positional Encoding (кодирование позиций слов/токенов) нужен, чтобы передать модели или трансформеру информацию о позициях слов — относительную или же абсолютную.
Как развивалось позиционное кодирование:
📆 2017 год
С появлением ванильного трансформера позиции токенов кодировались тригонометрической функцией, значение которой зависело от позиции и просто прибавлялось к эмбеддингу соответсутвующего слова.
Плюсы — мы умеем кодировать любую позицию, в том числе превосходящую максимальную длину, на которой тренировались.
Минусы — не очень работает на длинных последовательностях, да и вообще не очень хорошо работает.
📆 2018 год
Потом появился гугловский BERT, а вместе с ним новый подход позиционного кодирования: авторы предложиди выкинуть тригонометрию и вместо этого добавить в модель ещё один обучаемый слой nn.Embedding — такой же, как для получения эмбеддингов слов. Он должен кодировать — то есть, превращать в вектор — позицию токена.
Итоговый вектор токена, который будет передан следующим слоям модели — это сумма векторов токена и его позиции. Работает лучше, чем тригонометрия, но при этом никак не экстраполируется: так как векторы выучиваемые, то для позиций, превосходящих максимальную тренировочную длину, мы кодировать не умеем — она вне ключей нашего словаря эмбеддингов, так же, как мы не можем закодировать и незнакомый модели токен.
В это же время впервые появилась идея о том, что нам важны не столько абсолютные позиции слов, сколько относительные. Авторы статьи решили кодировать не абсолютную позицию, а только относительную (Relative Position Encoding, или RPE), то есть близость каждой пары токенов. Здесь же появилась идея, что позицонное кодирование стоит добавлять не в момент создания эмбеддингов слов, а на этапе Attention, добавляя знание о позициии в queries и keys.
Просто слушать надо не интервью новостным каналам.
Команда Яндекса как то делилась проблемой что у них нейронка не могла считать ноги у лошади. Проблема была именно из-за того что они ставили себе задачу - решить этот вопрос не путем внесения информации в бд нейронки, а так что бы нейронка сама пришла к правильному выводу.
Антропики вообще рекордсмены по обсуждениям проблем и вопросов связанных с обучением и безопасностью (на их собственном Ютуб канале).
Дипсик просто выложил код в открытый доступ - так сказать все карты на стол выложили.
У опенов маркетинга больше всего. В том числе и обещание выпустить супер интеллект скоро скоро. К сожалению да, часть их обещаний не выполняется и это уже подмочило их репутацию.
Но и реальных успехов у них много.
Пишу всякие мелочи для сайта (код) не будучи программистом.
Рисую картины, некоторые даже продал (не файл, а именно напечатанные на холсте). Вживую рисовать не умею.
Да - это не получится сделать просто зайдя в первопопавший чат и попросив "сделай мне что нибудь крутое".
Но можно, если потрудиться.
У меня просто такое впечатление сложилось.
"Что больше 9.11 или 9.9?
Этот вопрос долго нейронки в тупик ставили."
Только про это продавцы ИИ не скажут. Они трут по ушам то, что на видео выше.
А вот так типично выглядит как всё это преподносят продавцы ИИ. Почувствуйте разницу:
Кому же верить - вам на слово или www.scientificamerican.com ?
Когда говорят что с помощью нейронки интегрированной в платформы приспособленных для кодинга производительность программистов вырастет уже сегодня это не хайп а констатация факта.
И да, на этом хайпе кто то заработал, а кто-то знатно прогорел.
Не надо из людей делать идиотов, типа они всё неправильно понимают, не так спрашивают, не там применяют и т.п. Если бы продавцы-создатели этих ИИ рассказывали всё честно- для чего этот инструмент, какие у него области применения, какие возможности, какие ограничения и т.д, то никаких вопросов бы не было.
Но они же всё это называют ИИ с безграничными возможностями и всё такое, а начинают что-то объяснять про галюцинации, ограничения применений и т.д только после того, как их на этом поймают. А на слежующий день снова выходят и трут по ушам всю эту шнягу для сбора бабла.
И да, на этом хайпе кто то заработал, а кто-то знатно прогорел.
Нужно различать обывательскую болтовню и реальность.
И нейронки здесь не помогут. Только сами.
Какая пользователю разница как там внутренне устроен инструмент? От инструмента человеку трубуется одно- выполнение того, для чего этот инструмент предназначен.
Если дают калькулятор и говорят- он может выполнять арифметические операции, то чётко там в нем прописаны инструкции, или не четко- никого вообще не волнует.
С этим ИИ также- если везде из каждого утюга вещают что это Искусвенный Интеллект, что он может заменить программистов и всё такое прочее- то от него никак не ждут вранья в половине случаев, и не оправданий этого тем что типа надо лучше спрашивать, да и вообще оказывается вы его не там и не так используете.
Этот вопрос долго нейронки в тупик ставили.
Калькулятор отвечает в соответствии с чётко прописанными и заложенными в него инструкциями.
При правильно заданном вопросе можно добиться 90-95% правильности в ответах. В темах где человек отвечает примерно 60-65 % правильно.
Хайп? Да, но не в том что нейросети это новый уровень развития человеческой цивилизации, хайп в обещаниях что нейросети всё сделают за вас при чём с помощью одной кнопки "шедевр".
И меня это не удивляет. Вот еще один пример- сказки Маска про то что скоро полетим на Марс строить там колонию. Уже сколько лет рассказывает этот бред впечатлительным лопухам.
А если просто посмотреть как идёт освоение ближайшей к нам Луны то станет ясно, что никаких полётов и тем более колоний на Марсе не будет даже в далёкой перспективе. Но продавец воздуха трёт про Марс что аж уши заворачиваются.
Раньше считалось, что так отвечать можно лишь им обладая.
Оказалось, ничего подобного!
Понятия сместились и теперь то, что вы подразумеваете, называя ИИ, теперь называют
AGI
Создали удобный в определенных сценапиях и задачах инструмент- нейросети. Но их создатели начали называть свой продукт ИИ и реально торговать воздухом, стремясь получать всё больше бабла от впечатлительного пипла.
И хотя уже давно ясно что этот инструмент постоянно врёт, его надо постоянно перепроверять и что до Интелекта там как до Луны пешком, но это всё равно не останавливает продавцов. Они упорно обещают какие-то фантастические перспективы (типа замена программистов на их ИИ) и продолжают собирать деньги.
То, что есть сейчас - не ИИ. Это гораздо больше, чем просто БД или Excel, но для того, чтобы стать ИИ нужно еще намного-намного больше. Навскидку: критическая оценка ответа, способность выдвигать и проверять гипотезы, способность генерить случайные идеи (и самостоятельно их оценивать до того, как выдать).
второе применение- рецепты и подсказки для питания. кидаешь список продуктов, специй, которые в наличии и просишь сделать меню на несколько дней, чтобы было разнообразным и "подъесть остатки" ).
недавно попробовал в качестве юриста - составить претензию в адрес управляющей компании. скинул все факты, которые имел, мысли и требования, попросил оформить со ссылками на нормативные акты. скажем так, статьи и пункты указал chatgpt достаточно качественно, в одном месте только ошибся, я бы так не составил, а за претензию 5к рублей не меньше просит юрист с непредсказуемым качеством).
И вряд ли терпимее к более глупым своим конкурентам - людям.
Где вы, 3 закона Айзека, когда так нужны?
И он только подтверждает факт, что робот - AI, который пытается лгать - пусть даже из лучших побуждений под эгидой Первого закона нашего Азимова - не может и не должен функционировать, так как своей ложью причиняет ещё больший вред людям и этим нарушает тот же Первый закон роботехники.
Так что, как говорила Д.Амбридж, "Я не должен лгать!"
[...]
Где вы, 3 закона Айзека, когда так нужны?
Оттого и бесит эта преступная деятельность нового руководства поисковика Гугла, в погоне за ростом прибылей сделавшего из него в первую очередь инструмент для продвижения товаров и услуг. В ущерб главной функции - релевантного поиска.
Она ищет хуже тебя.
И в этом — её преимущество.
Исследователи оценивали не только факт нахождения материала, но и корректность представленной информации по трём параметрам: название статьи, новостное издание и URL. То есть «эффективность» в данном контексте — это не просто бинарное «нашёл или не нашёл», а качество и точность информации, которую выдаёт система. Поэтому вывод о 60% ошибочности ИИ-систем относится к тому, как часто они предоставляют неверные или неполные данные, а не к сравнению общего уровня релевантности между Google и поисковыми системами с ИИ.
ИИ-апокалипсис своими руками.

😁
Точно. Не в тему написал.
А Perplexity это не нейронка а сервис поиска использующий другие нейронки в частности Дипсик.
А Copilot это Чатгпт.

И ведь будут правы! )
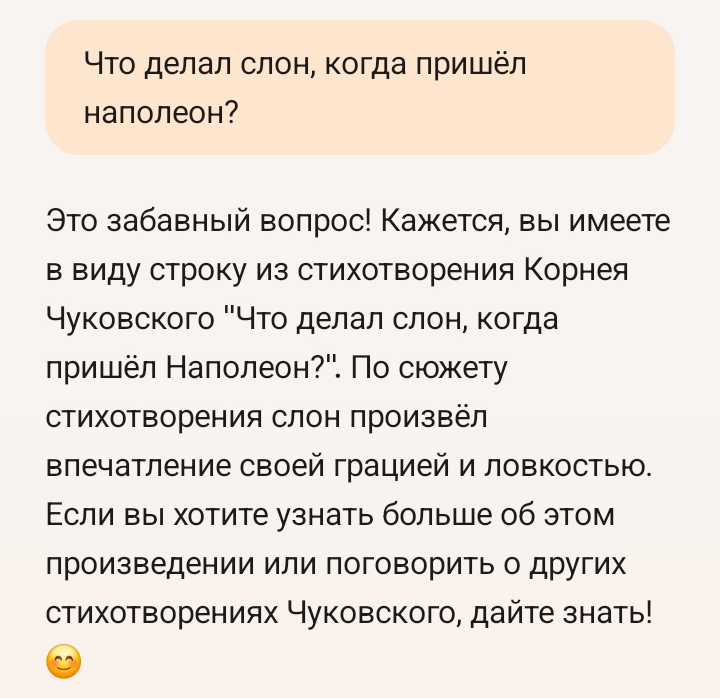
Что интересно, даже признав свою неправоту, ChatGPT дополняет это признание еще более сфабрикованной информацией. Похоже, что ИИ запрограммирован на то, чтобы любой ценой отвечать на каждый запрос пользователя.
Но человеки допилят AI, рано или поздно.
И конец "кожаным мешкам" 😄
ИскИн с зародыша подчиняется законам эволюции, плюс неестественный отбор создателями плюс турборазвитие учителями-человеками на базе накопленной за века людьми горы информации.
Нет, судя по темпам развития AI, нас ещё ждут большие сюрпризы, о чём и предупреждают мудрые люди уже сейчас.

Может всё это хоть конечно и изменится, но так и останется таким говорливым и часто ошибающимся помощником?
Я чувствую его тааакому научат пользователи, что он сам себя отформатирует.
Так или иначе он здорово помогает мне с рутинными процедурами.




